
PH.D. DISSERTATION PROPOSAL
Privacy-Preserving Machine Learning
for Skeleton-Based Data
Thomas Carr
Advised by Dr. Depeng Xu
Committee Members:
Dr. Aidong Lu • Dr. Xi "Sunshine" Niu • Dr. Minwoo "Jake" Lee • Dr. Jeremy
Holleman
December 5th, 2025
Proposal Outline
1. Introduction
Motivation & threat model.
2. Research Questions
The core problems this dissertation addresses.
3. Study 1
Explanation-Based Anonymization (PAKDD 25).
4. Study 2
Privacy-centric Motion Retargeting (ICCV 25).
5. Study 3
Disentangled Transformer Motion Retargeting.
6. Summary
Timeline & Broader Implications.

Background: Skeleton Data Utility
What is Skeleton Data?
Skeleton data: joint coordinates over time, no RGB pixels.
Why is it important?
- VR: Avatar control.
- Healthcare: Gait and rehab monitoring.
- Surveillance: Security and activity monitoring.

O. Seredin, A. Kopylov, S.-C. Huang, and D. Rodionov, “A skeleton featuresbased fall detection using microsoft kinect v2 with one class-classifier outlier removal,” ISPRS - International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol. XLII-2/W12, pp. 189-195, 05 2019.
The Privacy Threat
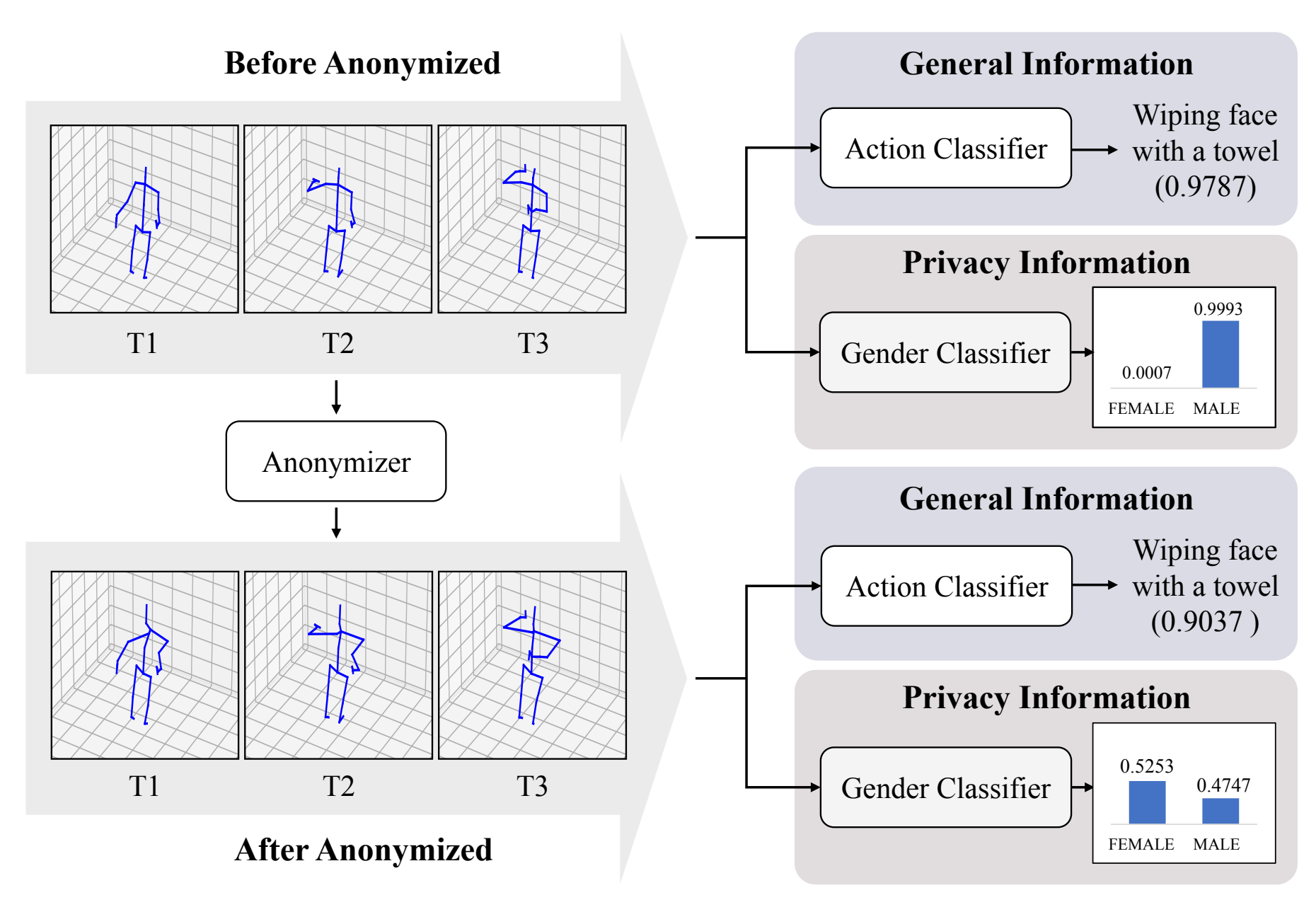
S. Moon, M. Kim, Z. Qin, Y. Liu, and D. Kim, “Anonymization for skeleton action recognition,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2023.
The "Anonymous" Myth
| Assumption: | No video → no privacy risk |
| Reality: | Motion is a biometric |
- Static: limb lengths, bone ratios.
- Dynamic: gait frequency, posture.
Motion alone is enough to track users or infer sensitive health attributes.
Attack Vectors
We analyze three primary threats to skeleton privacy.
1. Re-ID
Who?
Matching to database.
Accuracy: >80%*
2. Inference
What?
Predicting traits.
Accuracy: ~87%* (gender)
3. Linkage
Same person?
Cross-session tracking.
Accuracy: 74%†
* S. Moon, M. Kim, Z. Qin, Y. Liu, and D. Kim, “Anonymization for skeleton action recognition,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2023.
† T. Carr, A. Lu, and D. Xu, “Linkage attack on skeleton-based motion visualization,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, pp. 3758-3762, 2023.
Evidence: The Linkage Attack (CIKM 23)
Unlabeled, Siamese network, cross-session linkage.
T. Carr, A. Lu, and D. Xu, “Linkage attack on skeleton-based motion visualization,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, pp. 3758–3762, 2023.
Research Gaps
Gap 1: Varying Joint Sensitivity
Traditional methods apply uniform noise, ignoring that joints have varying sensitivity. Global perturbation disproportionately degrades utility.
Gap 2: Attacker Agnostic Anonymization
Existing techniques rely on "white-box" assumptions. These fail against unknown, real-world attack vectors where the model is black-box.
Gap 3: Architectural Limitations
Modern ML uses Transformers for temporal dependencies, yet privacy methods still rely on frame-by-frame CNNs, missing long-term context.
Gap 4: Kinematic Inconsistency
Treating skeletons as unstructured vectors ignores biomechanics, leading to impossible motions like bone stretching and jitter.
Research Questions
RQ1: Explainable AI-guided anonymization
How can explainable AI techniques identify privacy-sensitive joints to enable targeted anonymization that overcomes the utility loss of uniform perturbation methods?
RQ2: Motion-retargeting as a defense
How can motion retargeting serve as an attacker-agnostic defense by effectively disentangling user identity from motion content without reliance on specific threat models?
RQ3: Transformer-based anonymization
How can transformer architectures be leveraged to capture long-horizon dependencies and enforce kinematic consistency, thereby strengthening the privacy-utility balance and ensuring physical plausibility?
Proposed Studies
Based on the research questions, we propose three studies.
Study 1
Explanation-Based Anonymization
Targeted masking using Integrated
Gradients.
Published in PAKDD 25
Study 2
Privacy-centric Motion Retargeting (PMR)
Implicit disentanglement via
CNNs.
Published in ICCV 25
Study 3
Disentangled Transformer (TMR)
Explicit disentanglement via Transformers.
Study 1: Introduction
The Goal
To significantly reduce the performance of the Threat Model (Privacy) while maintaining high performance on the Utility Model (Action Recognition).
The Approach
We train two competing deep learning models: a Utility Model and a Threat Model. Our goal is to reduce the Threat Model's accuracy while keeping the Utility Model's accuracy high.
Hypothesis: Targeted noise (based on sensitivity) beats uniform noise on the privacy–utility trade-off.
- Train Utility and Threat models.
- Use XAI to identify privacy-sensitive joints.
- Add noise to those joints.
Methodology: Training Two Models
We train two independent deep learning models to capture the opposing goals of utility preservation and privacy protection.
Utility Model ($f^U$)
Task: Action Recognition
- Labels: 60 Actions.
- Goal: Maximize Accuracy.
Threat Model ($f^P$)
Task: Re-Identification
- Labels: 40 User IDs.
- Goal: Minimize Accuracy.
Technical Foundation: Integrated Gradients
Integrated Gradients (IG):
Key Properties:
- Attribution: Explains predictions by attributing importance to input features.
- Axioms: Satisfies Completeness and Sensitivity.
- Applicability: Works with any differentiable model (e.g., SGN).
- Efficiency: Suitable for high-dimensional data like skeletons.
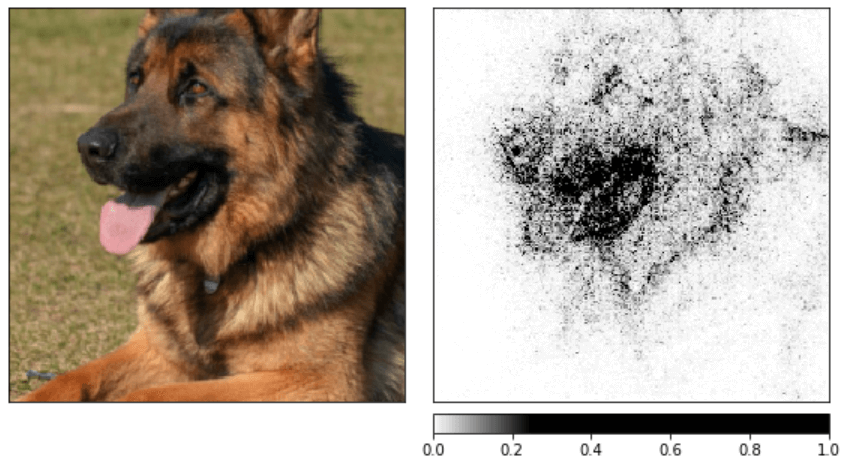
Image adapted from Gilbert Tanner, "Interpreting PyTorch models with Captum," 2019.
Technical Foundation: Differential Privacy
Definition: A randomized function $\mathcal{M}$ satisfies $(\epsilon, \delta)$-differential privacy if for all neighboring datasets $D$ and $D'$:
$ P(\mathcal{M}(D) \in O) \leq \exp(\epsilon) \cdot P(\mathcal{M}(D') \in O) + \delta $
Where $\epsilon$ denotes privacy budget and $\delta$ is a broken probability.
Our Application:
- Budget Distribution: Total privacy budget $\epsilon$ is distributed across joints.
- Targeted Noise: Sensitive joints receive a smaller budget (more noise).
- Gaussian Mechanism: $\mathcal{M}(X) = f(X) + (Z_1,\ldots,Z_k)$
C. Dwork and A. Roth, “The algorithmic foundations of differential privacy,” Foundations and Trends in Theoretical Computer Science, vol. 9, no. 3-4, pp. 211–407, 2014.
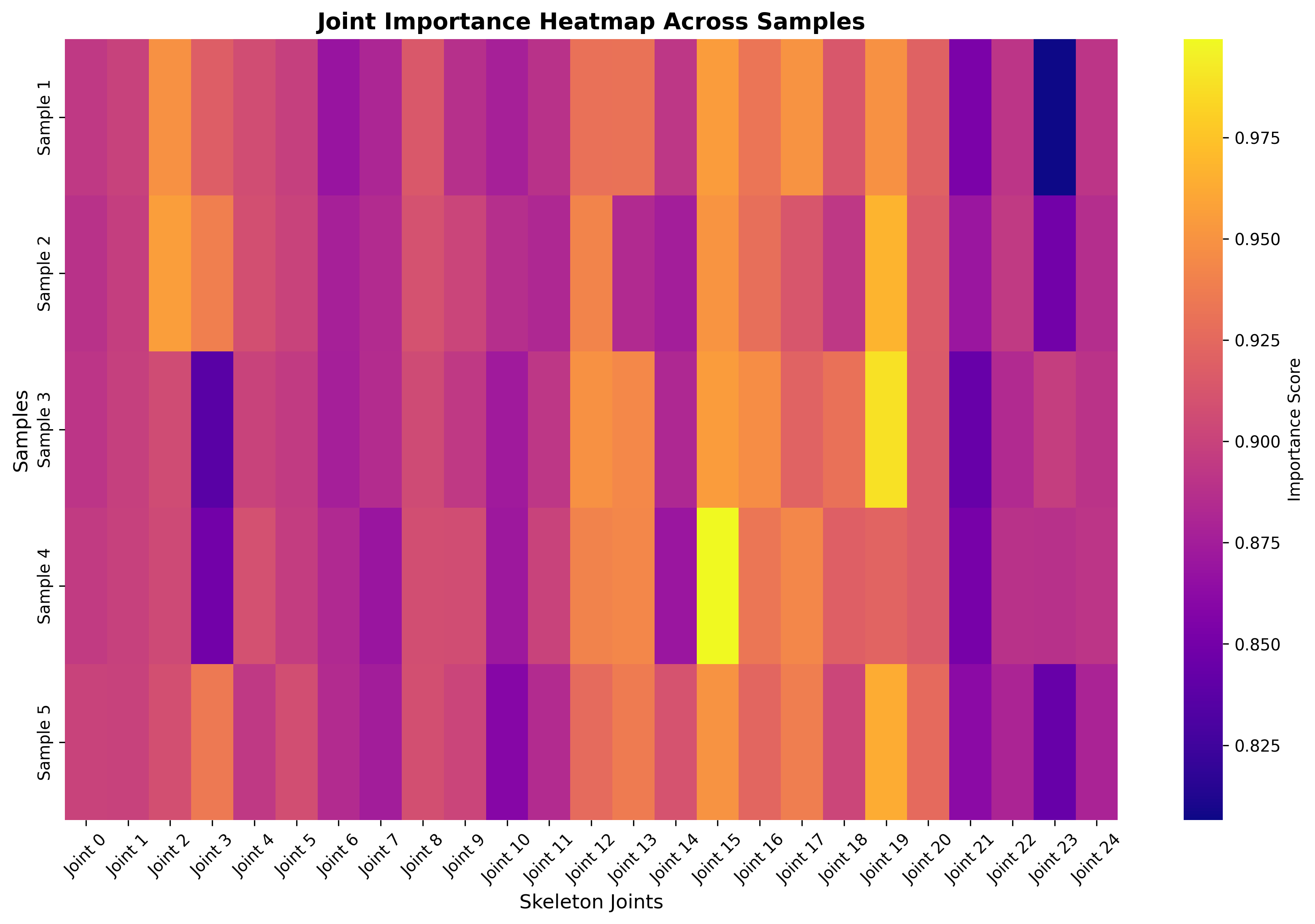
Methodology: Sensitivity Score
We use Integrated Gradients (IG) to generate per-joint attributions ($\phi$).
IG integrates gradients along a path from a baseline to the input, quantifying how much each joint contributes to the model's prediction.
High $\psi_j$ = Target for masking/noise.
(Risky for privacy, not crucial for utility)
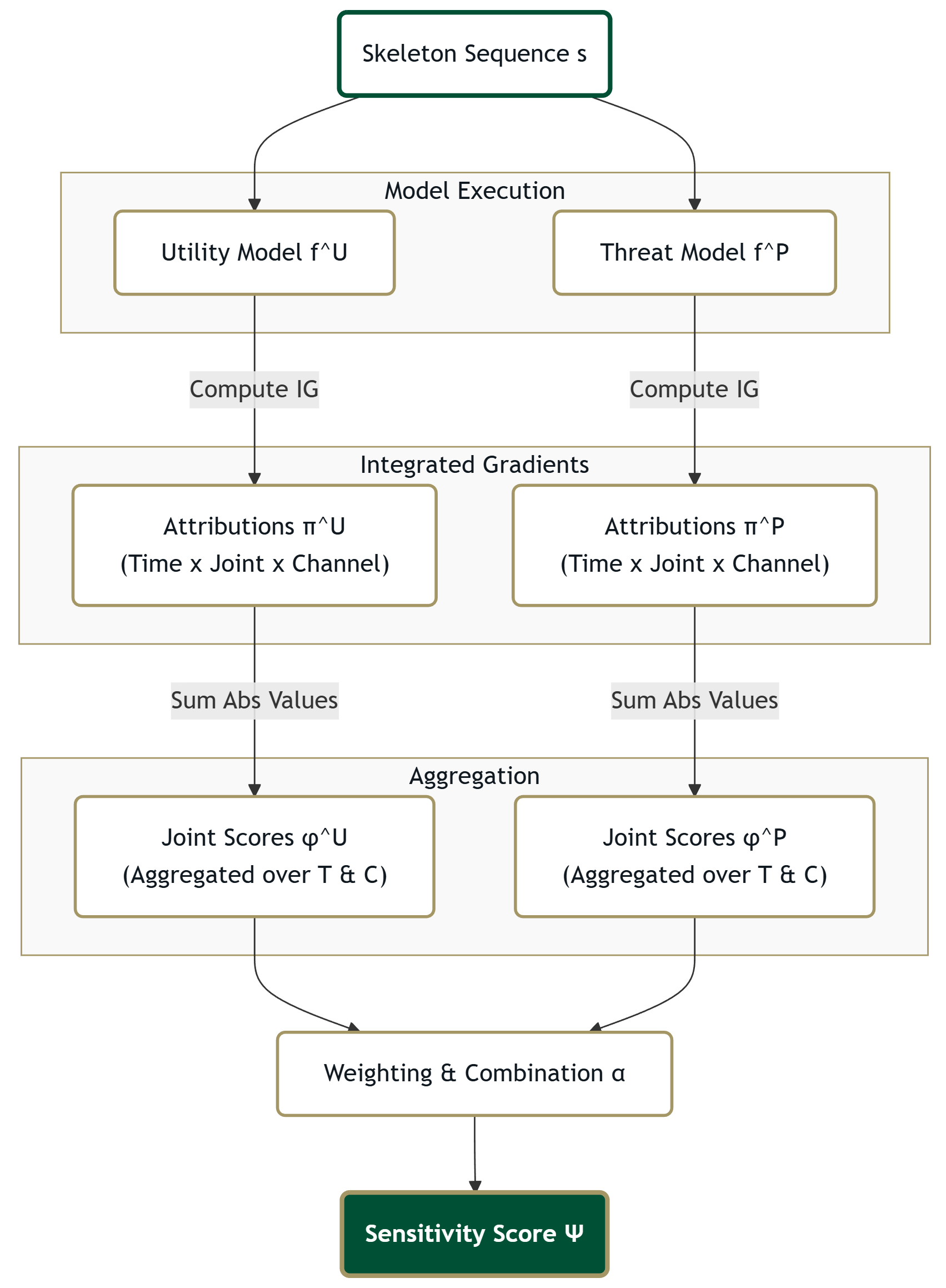
Approach 1: Smart Masking
Sets the most sensitive joints to zero.
- Step 1: Sort joints by Sensitivity Score ($\psi_j$).
- Step 2: Select top $\beta\%$ as Sensitive Group ($G_s$).
- Step 3: Mask them ($s_j = 0$).
Definitions:
- $\psi_j$: Sensitivity Score.
- $\beta$: Percentage of joints to mask.
- $G_s$: Sensitive Group (masked).
- $G_n$: Non-Sensitive Group (kept).
Approach 2: Group Noise
Strategy: Split joints into two groups.
- Sensitive ($G_s$): Top $\beta\%$ joints. Receives More Noise.
- Non-Sensitive ($G_n$): Remaining joints. Receives Less Noise.
Definitions:
- $\epsilon$: Total Privacy Budget.
- $\epsilon_s, \epsilon_n$: Budget for sensitive/non-sensitive groups.
- $\beta$: Proportion of sensitive joints ($|G_s|/J$).
- $\gamma$: Noise Ratio ($\epsilon_s / \epsilon_n$).
Problem: Jittery Motion
High noise on specific joints causes intense fluctuations and bone stretching.
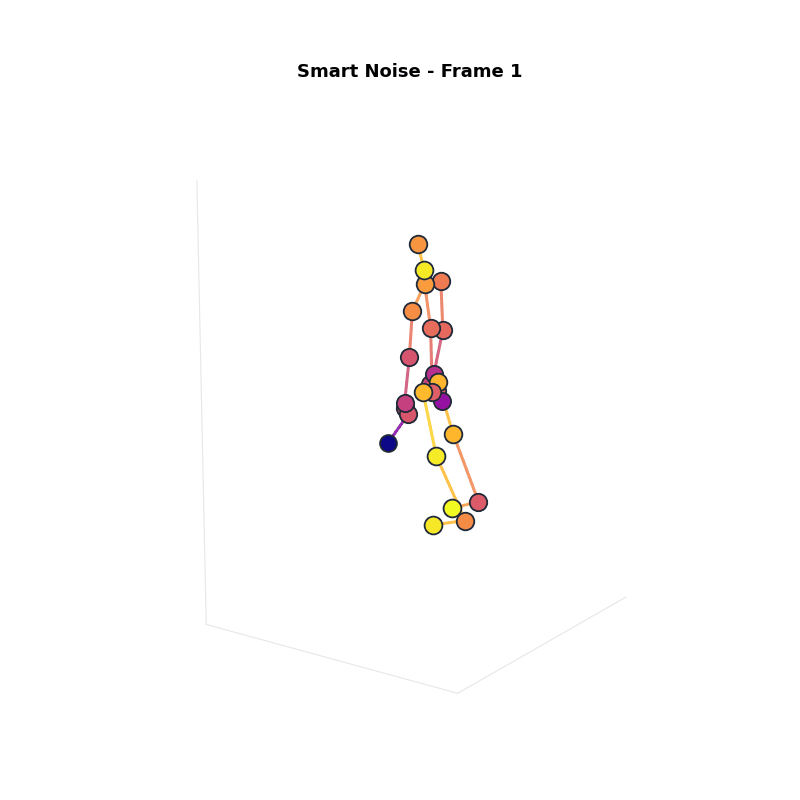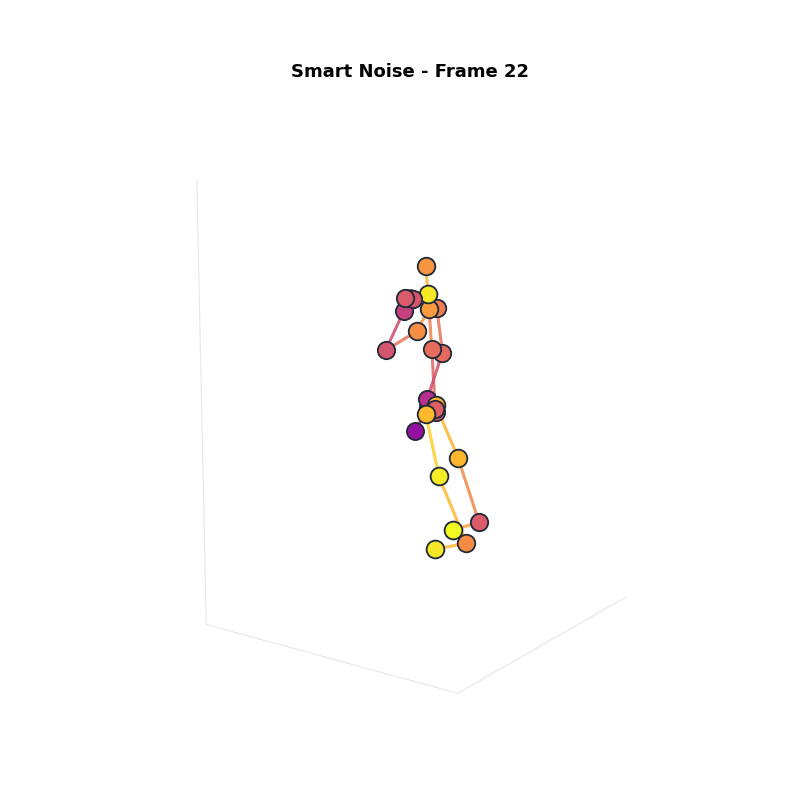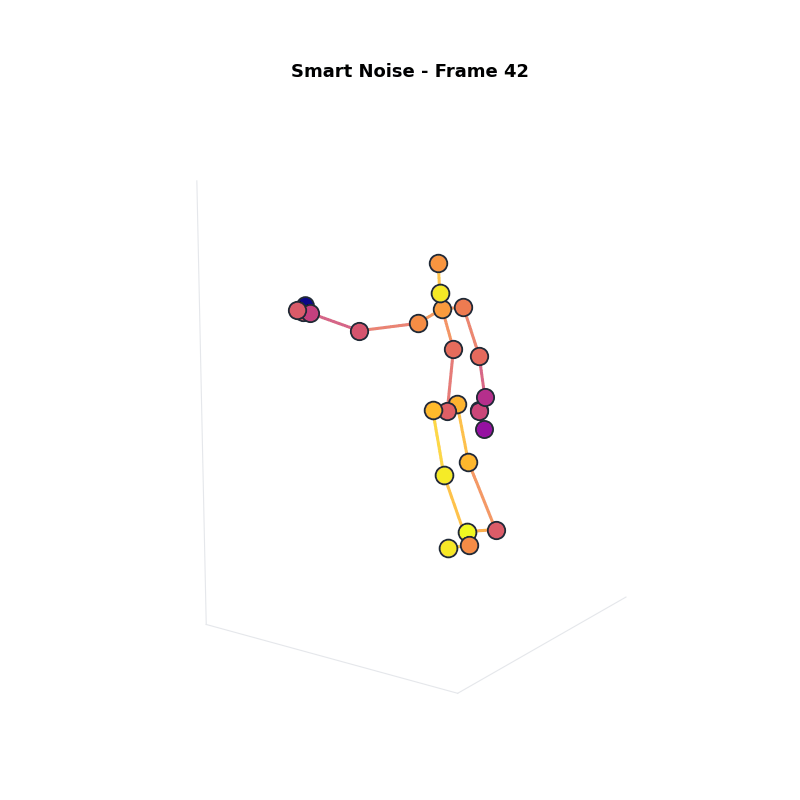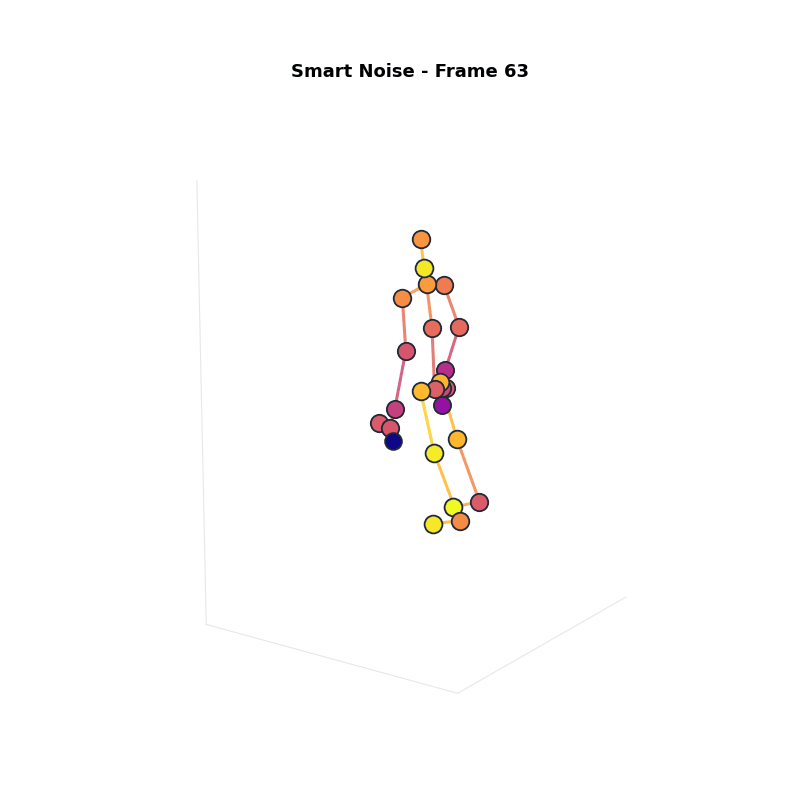
Approach 3: Smart Noise
Intuition: Continuous noise scaling based on sensitivity.
Definitions:
- $\psi_j$: Sensitivity Score.
- $\epsilon$: Privacy Budget.
- $\sigma_j$: Noise magnitude for joint $j$.
Compared to Group Noise: better visual quality, still strong privacy.
Experimental Setup
Datasets & Protocols
- NTU-60 & NTU-120: Large-scale skeleton datasets.
- Protocols: Cross-Subject (CS) and Cross-View (CV).
Model
- Backbone: Semantics-Guided Neural Network (SGN)*.
Baselines
- Consumer VR: Mask all but Head + Hands (Left+Right).
- Naive Noise: Uniform Gaussian noise.
Hyperparameters Tested
- $\alpha$ (Weighting): 0.1, 0.5, 0.9
- $\beta$ (Masking %): 0.1, 0.2, 0.3, 0.4, 0.5
- $\gamma$ (Noise Ratio): 0.01, 0.03, 0.05, 0.07, 0.1
- $\sigma$ (Smart Noise): 0.01, 0.05, 0.1
Metrics
- Privacy: Re-ID Accuracy (Lower is better).
- Utility: Action Rec. Accuracy (Higher is better).
* P. Zhang, C. Lan, W. Zeng, J. Xing, J. Xue, and N. Zheng, “Semantics-guided neural networks for efficient skeleton-based human action recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1112-1121, 2020.
Study 1 Results (NTU-60)
Key point: Smart Noise offers the best balance of privacy, utility, and visual quality.
| Method | Action Rec. $\uparrow$ | Re-ID $\downarrow$ | Qualitative Analysis |
|---|---|---|---|
| Original Data | 94.72% | 81.58% | - |
| Consumer VR (3 Joints) | 90.82% | 58.97% | Poor (Not visualizable) |
| Naive Noise | 90.04% | 76.08% | Good (Smooth) |
| Smart Masking | 81.23% | 21.82% | Poor (Missing limbs) |
| Group Noise | 72.20% | 12.70% | Poor (Jittery) |
| Smart Noise | 79.97% | 28.24% | Good (Smooth) |
Hyperparameters: $\alpha=0.9, \beta=0.2, \gamma=0.03, \sigma=0.01$.
AnonVis Demo (ISMAR 25)
We validate not just numbers, but how the motion looks to humans.
Interactive Visualization
To validate visual quality, we built a VR pipeline.
- Pipeline: Skeleton data is processed in Blender then loaded into Unity.
- Mapping: Same mesh, different privacy transformations to isolate motion artifacts from mesh deformations.
- Result: Users can visually distinguish actions even with high noise.
Study 1: Summary & Contributions
Contributions
- Methodology: First use of Integrated Gradients for skeleton privacy.
- Technique: Developed Smart Masking, Smart Noise, and Group Noise.
- Validation: AnonVis VR tool for human-in-the-loop evaluation.
- Outcome: Re-ID reduced by ~84% in white-box settings while preserving useful action recognition.
Limitation: White-Box
While effective, Study 1 relies on knowing the attacker's model parameters.
We need a defense that works without knowing the attacker (Black-Box).
This motivates Study 2: can we defend against unknown attackers?
The Pivot: Motion Retargeting
The Goal
Create an anonymization method that works against unknown attackers.
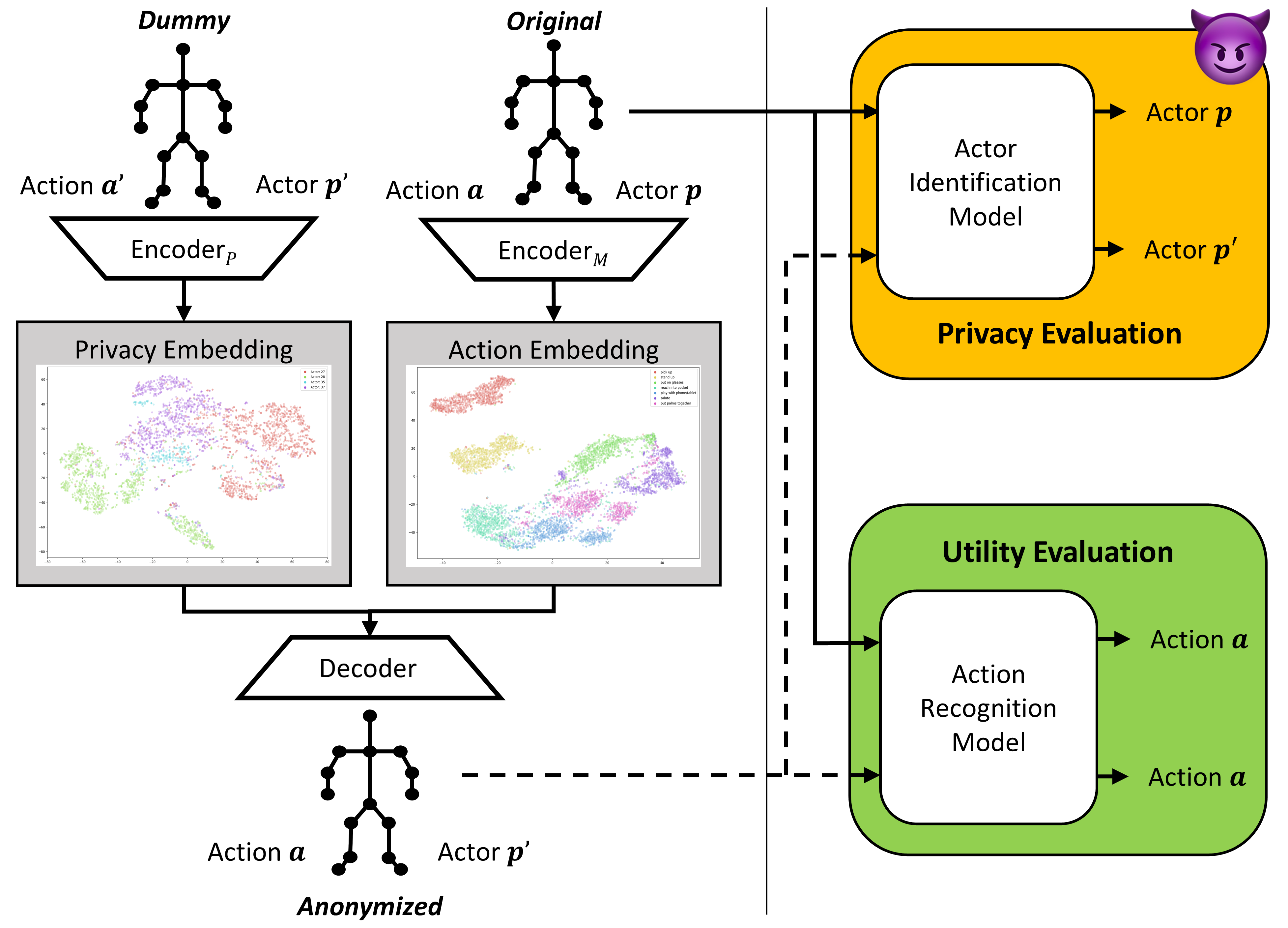
The Idea: "Don't Hide. Swap."
We transfer the user's motion onto a "Dummy" skeleton.
By definition, the output skeleton has none of the User's structural PII (limb lengths, ratios).
Background: Motion Retargeting
The Objective
- Perform the MR Switch ($a \to p'$).
- Ensure the two parts (Motion & Identity) are completely disentangled.
Challenge: We use Adversarial & Cooperative Learning to ensure the Motion Encoder doesn't accidentally learn Identity.
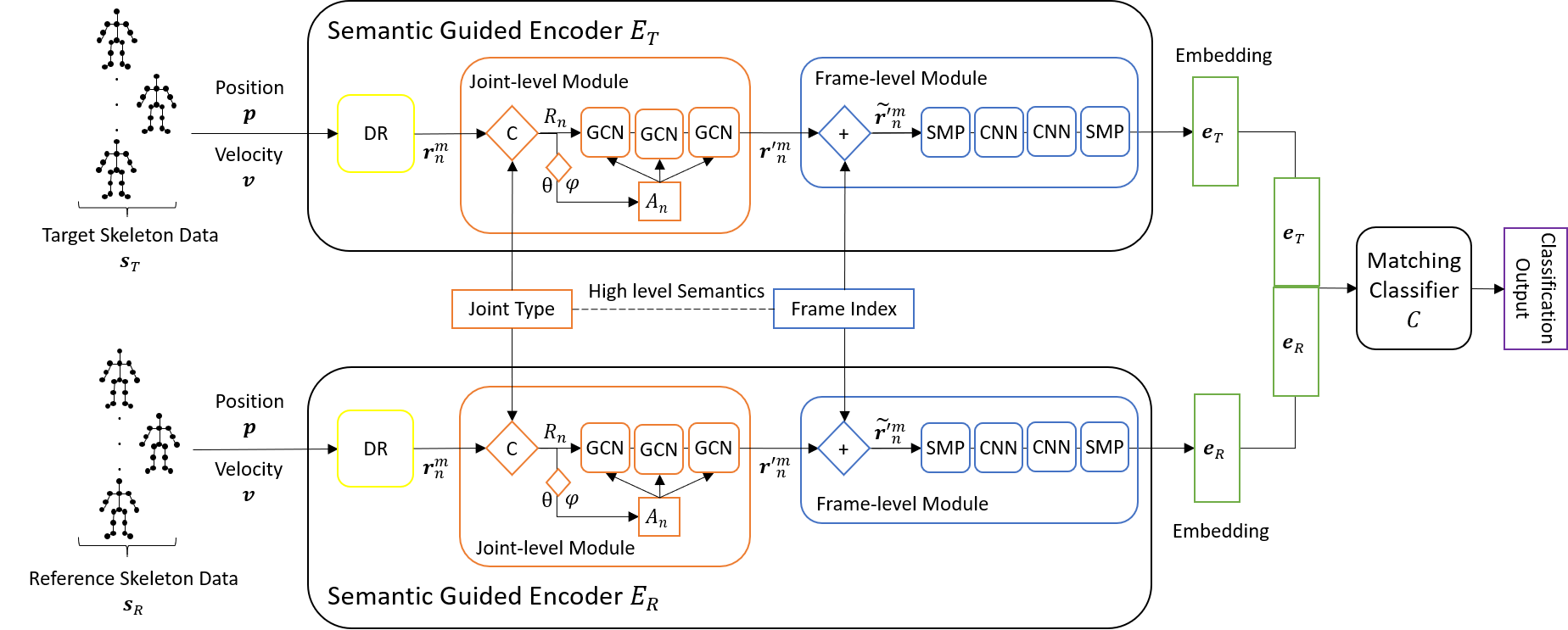
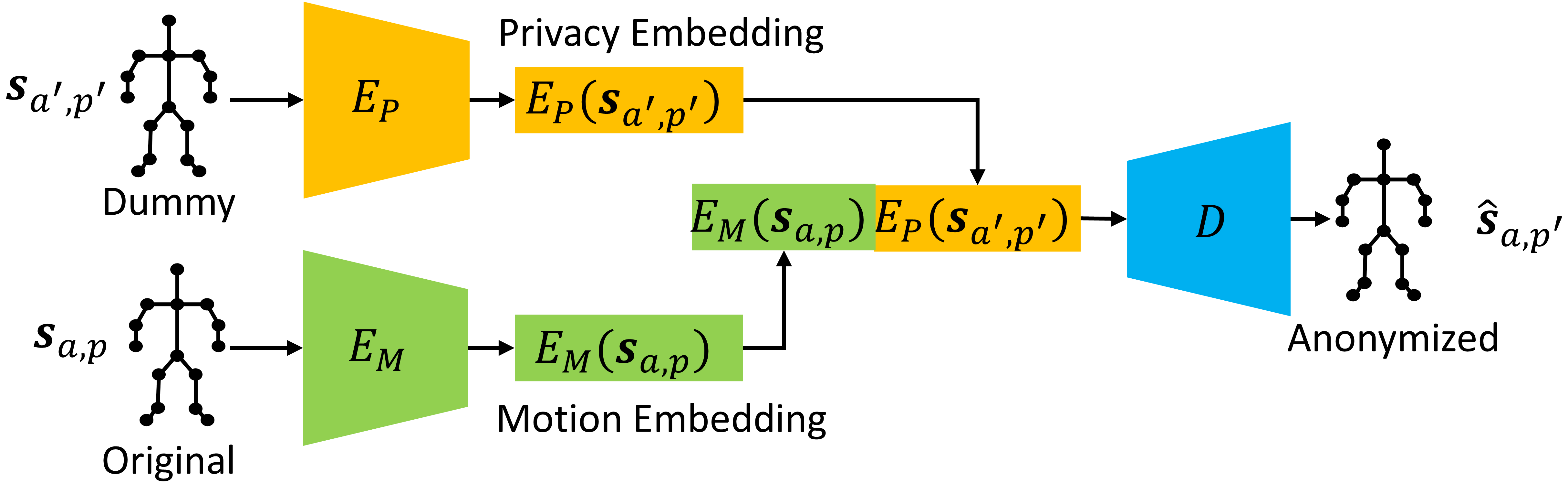
Architecture: Dual Encoders
We use two separate CNN encoders to split the input features.
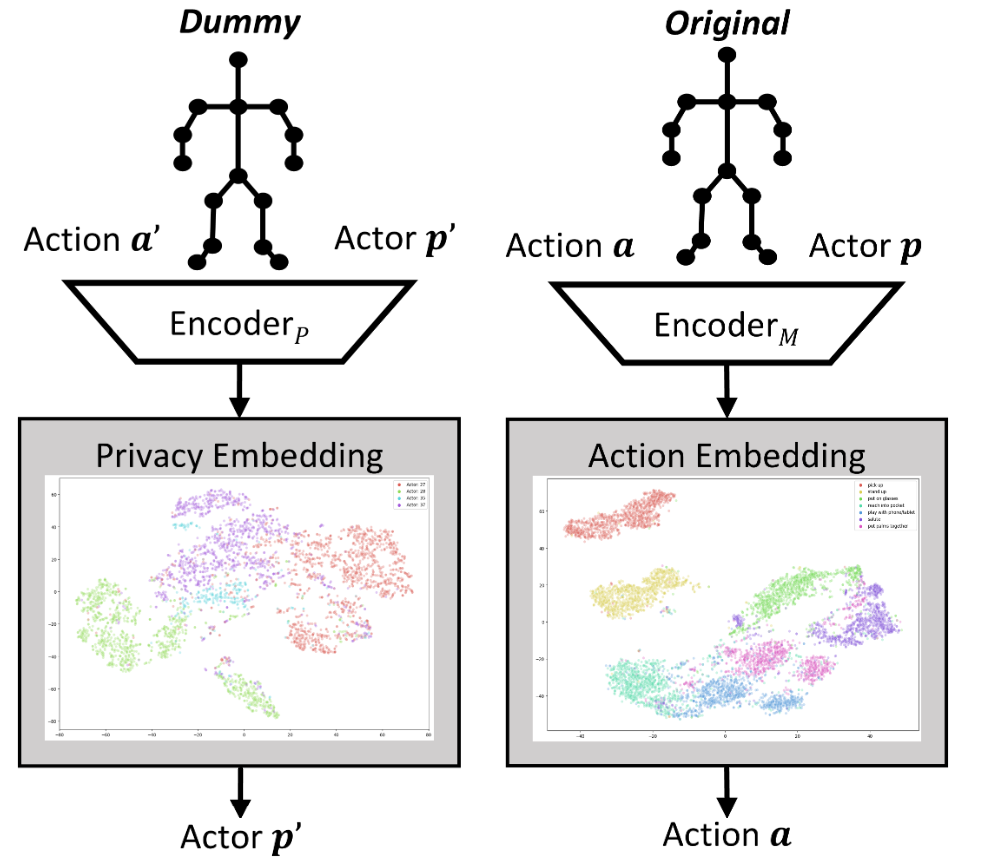
Motion Encoder ($E_M$)
Takes the Source Skeleton. Trained to extract Temporal Dynamics ($a$).
Privacy Encoder ($E_P$):
Takes the Dummy Skeleton ($p'$). Trained to extract Structural Identity ($p'$).
Enforcing Disentanglement
We use an iterative game with 4 Classifiers operating on the embedding space to shape the latent space.
Cooperative (2)
Ensures Encoders learn their domain.
- $M(E_M) \to$ Predict Action
- $P(E_P) \to$ Predict Identity
Adversarial (2)
Ensures Encoders forget the other domain.
- $M(E_P) \to$ Fail Action
- $P(E_M) \to$ Fail Identity
Mechanism: Cross-Reconstruction
The Decoder ($D$) is CNN-based with upscaling (UNet-like without residuals).
Methodology: PMR Overview
We propose Privacy-centric Deep Motion Retargeting (PMR).
It is a CNN-based Autoencoder framework designed to disentangle motion from identity by using Adversarial/Cooperative Learning.
We also employ a GAN-style discriminator to ensure the generated skeletons are realistic and physically plausible.
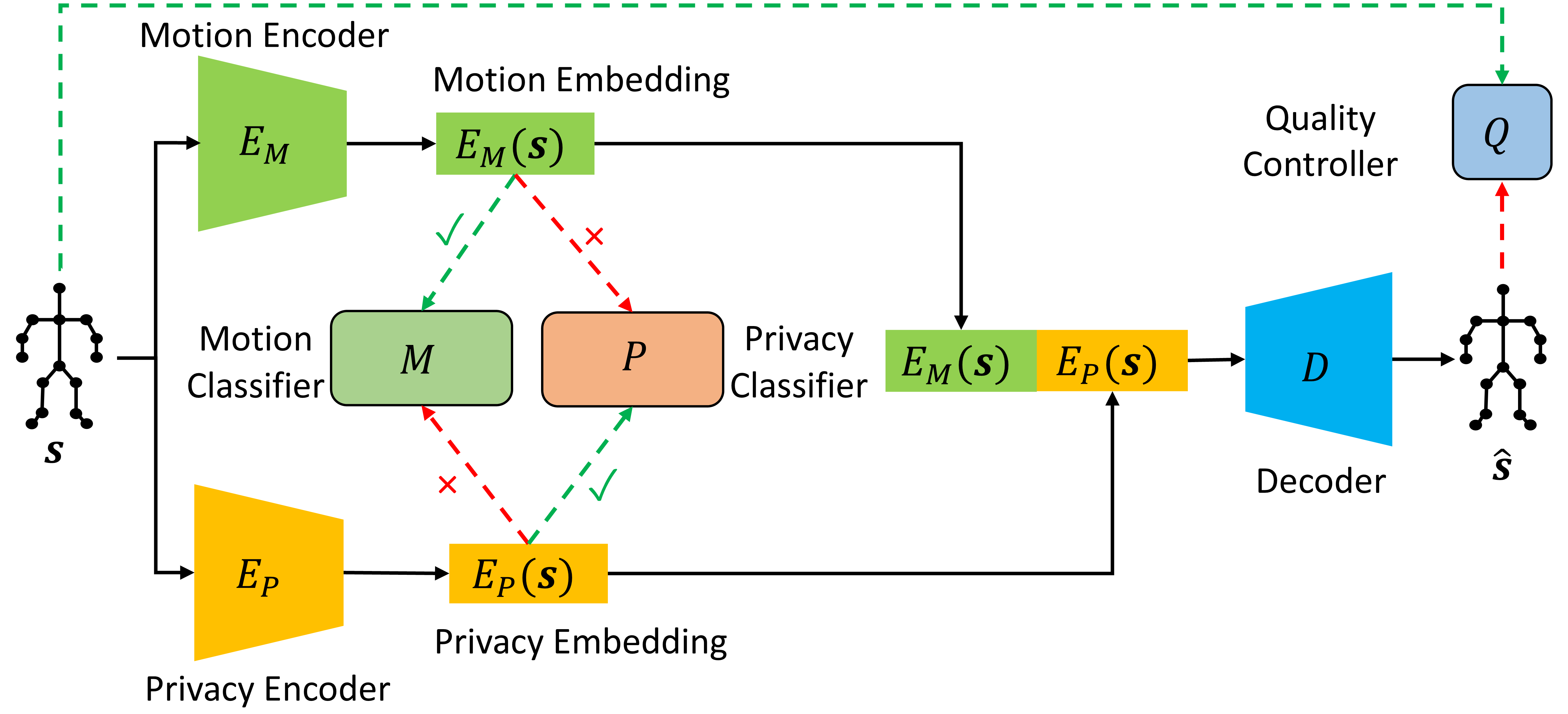
Training Procedure
The model is trained in 3 sequential phases.
| Stage | Components Trained | Objective |
|---|---|---|
| 1. Warm-up | $E_M, E_P, D$ | Autoencoder Reconstruction ($L_{rec}$) |
| 2. Separation | Classifiers ($M, P$) | Train classifiers on fixed embeddings. |
| 3. Alignment | All + $Q$ (Iterative) |
1. Update Discrim. ($Q, M, P$) 2. Update Gens ($E_M, E_P, D$) (+ Novel Smoothness & Latent Consistency Losses) |
Experimental Setup
Datasets
- NTU RGB+D 60 (CV Split)
- NTU RGB+D 120 (CV Split)
Metrics
- Privacy: Re-ID (Top-1/5).
- Utility: Action Recognition (Top-1/5), MSE.
Baselines
- Original: No defense.
- Moon et al. (2023)*: Adversarial Perturbation (White-Box model evaluated as Black-Box).
- DMR**: Standard Deep Motion Retargeting (No privacy loss).
* S. Moon, M. Kim, Z. Qin, Y. Liu, and D. Kim, “Anonymization for skeleton action
recognition,” in Proceedings of the AAAI Conference on Artificial Intelligence
(AAAI), 2023.
** K. Aberman, P. Li, D. Lischinski, O. Sorkine-Hornung, D. Cohen-Or, and B. Chen,
“Skeleton-aware networks for deep motion retargeting,” ACM Transactions on Graphics
(TOG), vol. 39, no. 4, pp. 62:1-62:14, 2020.
Results: Privacy-Utility Trade-off (NTU-60)
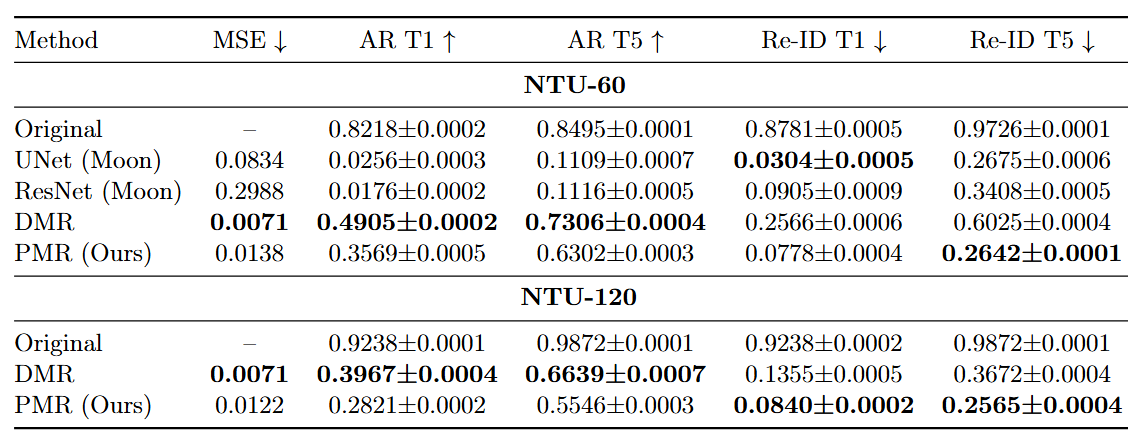
Ablation Study
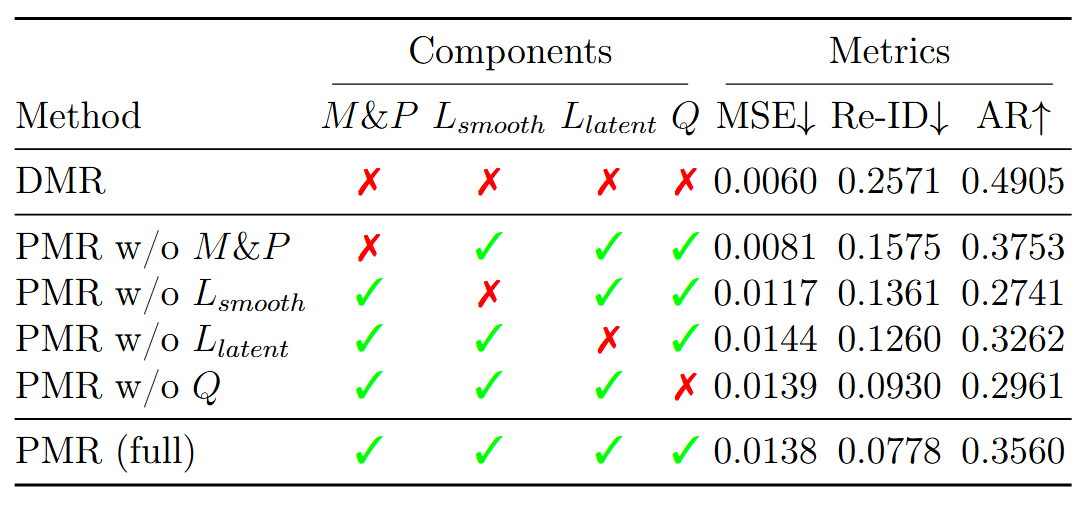
Key Findings
- w/o Classifiers: Re-ID (Top-1) jumps to 15.75%. Adversarial learning reduced privacy leakage.
- w/o Smoothness: AR (Top-1) drops to 27.41%. Smooth motion aids utility retention.
- w/o Latent Consistency: Encoders fail to separate domains.
- w/o Quality Discriminator: AR drops to 29.61%. Discriminator aids in utility retention.
*Note: Ablations performed on all novel components.
Qualitative Analysis
Visual Inspection:
PMR successfully alters the body structure (e.g., height, shoulder width) to match the dummy.
However, complex actions (e.g., "Drink Water") show loss of subtle motion cues, explaining the utility drop.
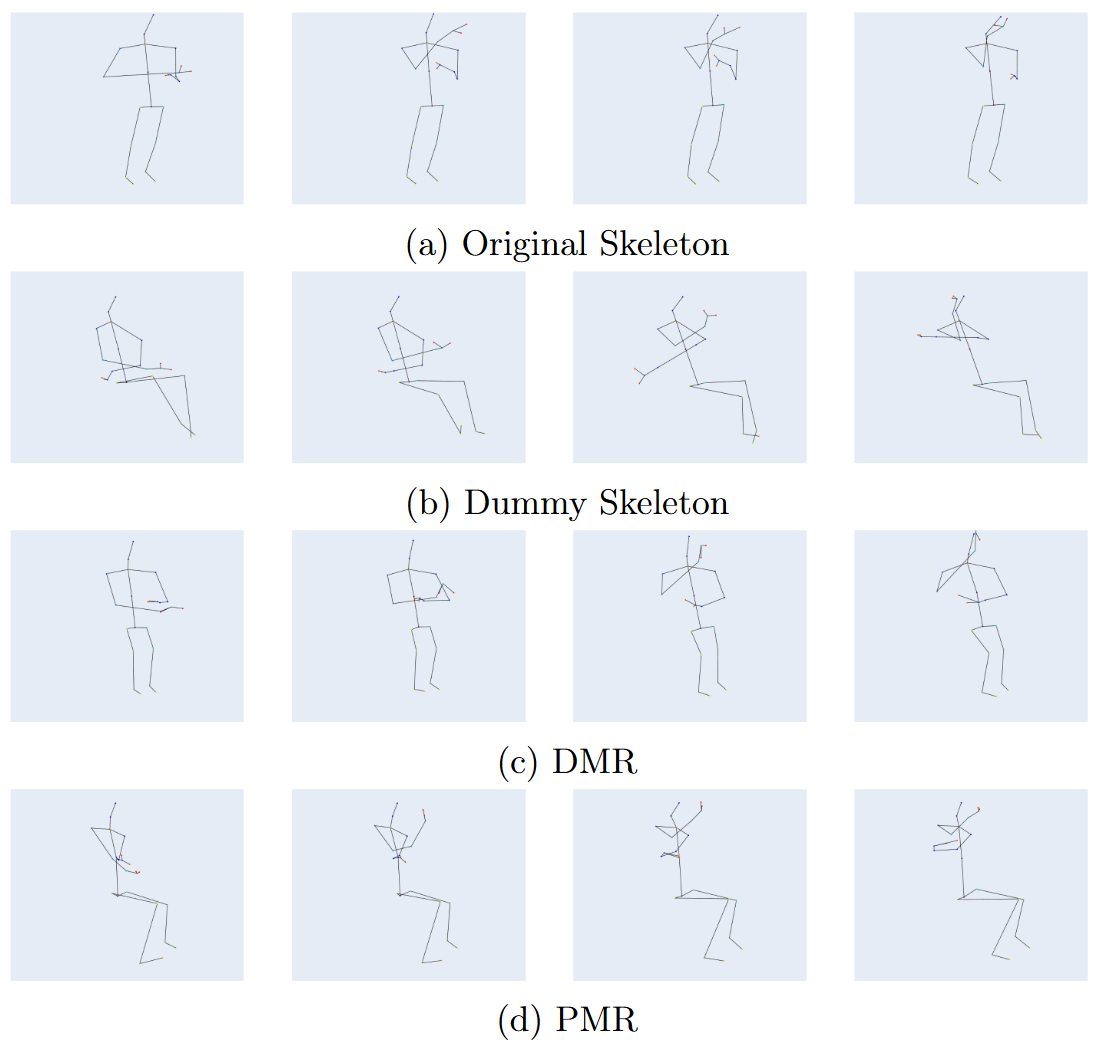
Study 2: Summary & Contributions
Contributions
- Methodology: First use of Motion Retargeting for Privacy.
- Technique: PMR Framework (Dual-Encoder + Adversarial).
- Outcome: Solved the Black-Box problem (Attacker Agnostic).
Limitation: Utility Gap
We achieved Black-Box Privacy, but AR accuracy (35%) is low.
Root Cause: CNNs struggle with long-range dependencies, and implicit adversarial separation is difficult to balance.
Closing the Gap: Transformers
1. Why Transformers?
Transformers capture global dependencies via Self-Attention. This boosts Action Recognition performance on complex sequences (addressing Study 2's weakness).
2. Autoregressive Generation
Retargeting requires temporal continuity. We use an Autoregressive Decoder to generate motion frame-by-frame, ensuring smoothness and consistency.
Proposed Architecture (TMR)
High-Level Flow: Feature Engineering -> Specialized Encoders -> Autoregressive Decoder
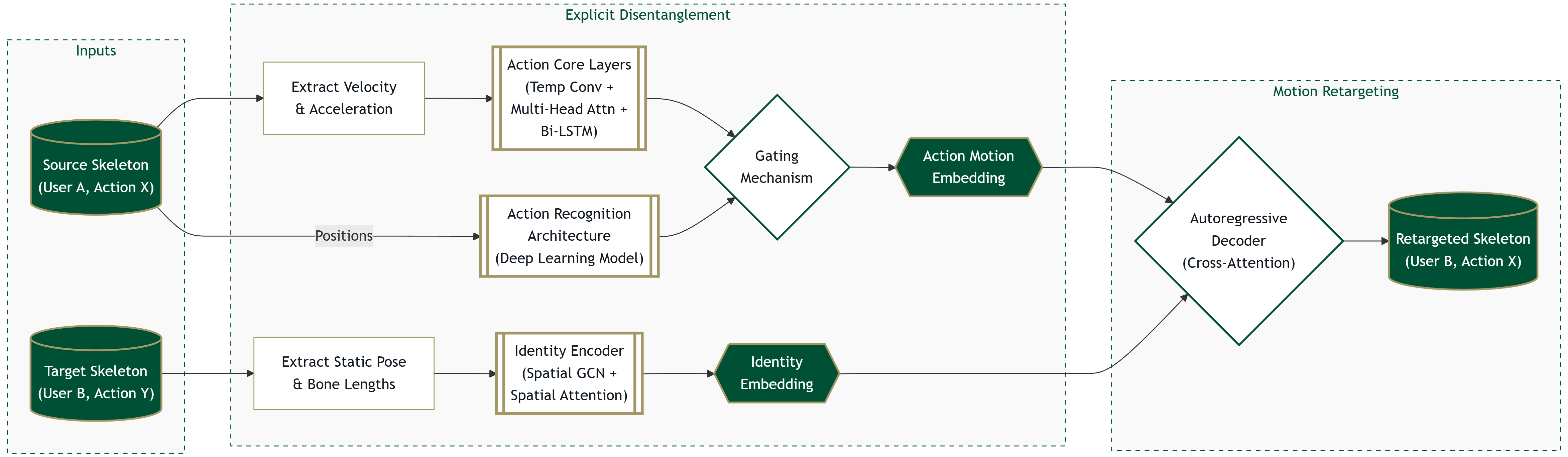
Difference from PMR: Sequential decoding ensures temporal continuity; Transformers handle long-range dependencies.
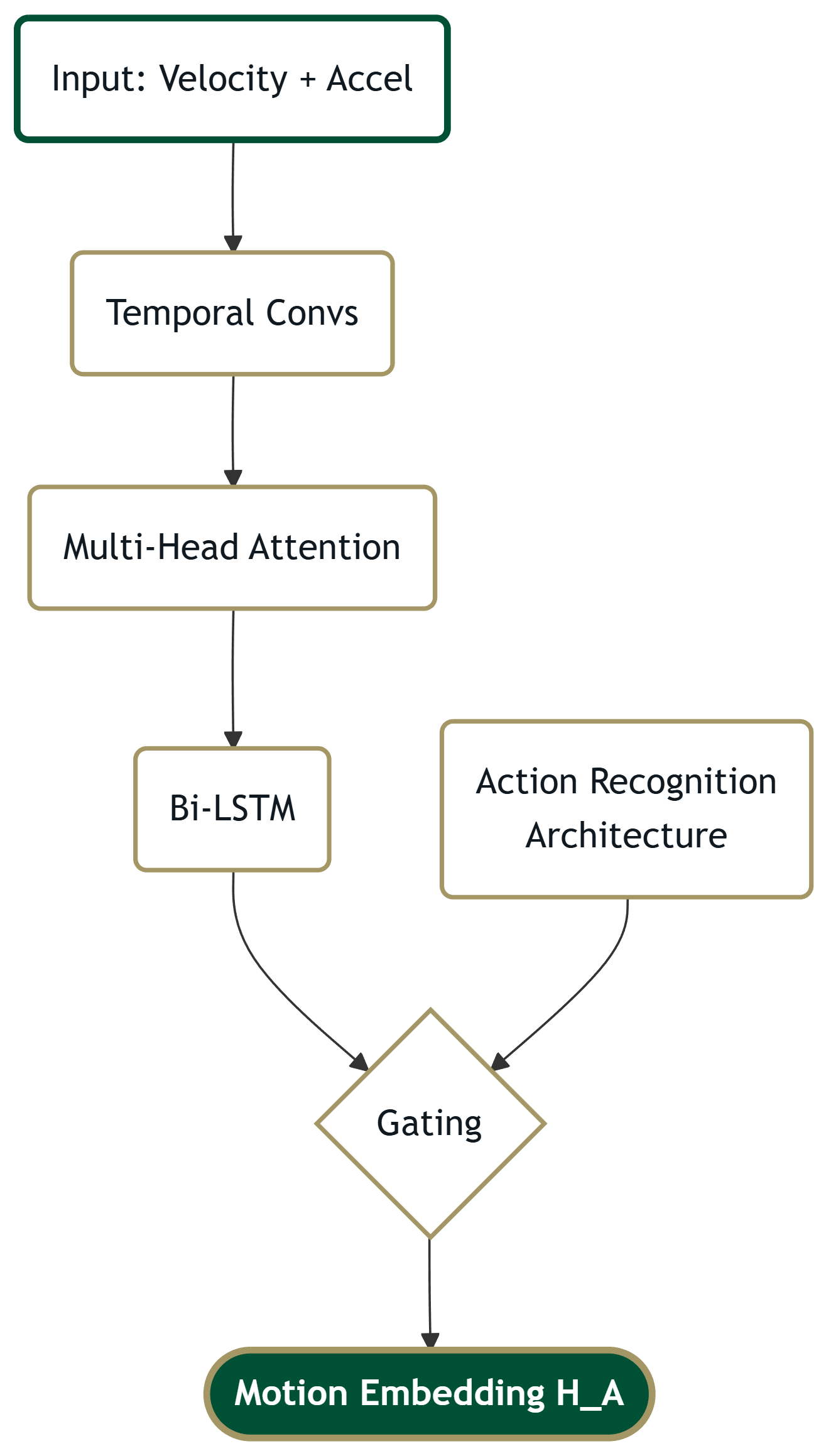
1. The Gated Action Encoder ($E_A$)
Inductive Bias: Dynamics
Input: Velocity ($V_t$) + Acceleration ($A_t$). No Static Pose.
Dimension: $H_{action} \in \mathbb{R}^{T \times 256}$.
Iterative Training Stream
We fuse the LSTM stream with features from an Iteratively Trained Action Recognition Model (e.g., MixFormer) via a learned gate.
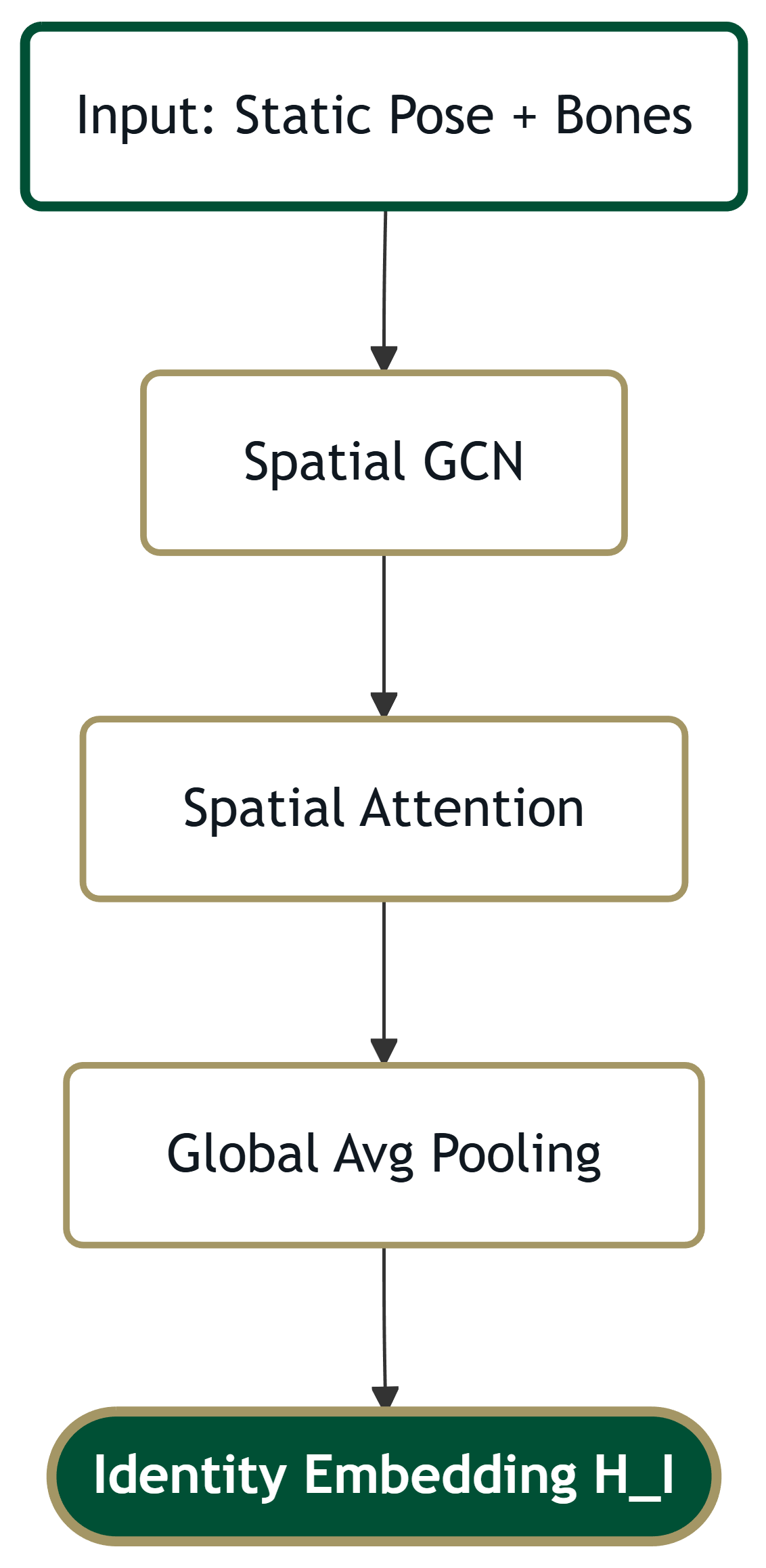
2. The Identity Encoder ($E_I$)
Inductive Bias: Spatial Structure
Input: Position ($P_t$) + Bone Lengths.
Dimension: $H_{identity} \in \mathbb{R}^{1 \times 64}$ (Small to limit leakage).
Spatial Attention
A Spatial Attention mechanism learns the topological relationships between bones (e.g., arm length vs leg length ratios), ignoring temporal dynamics.
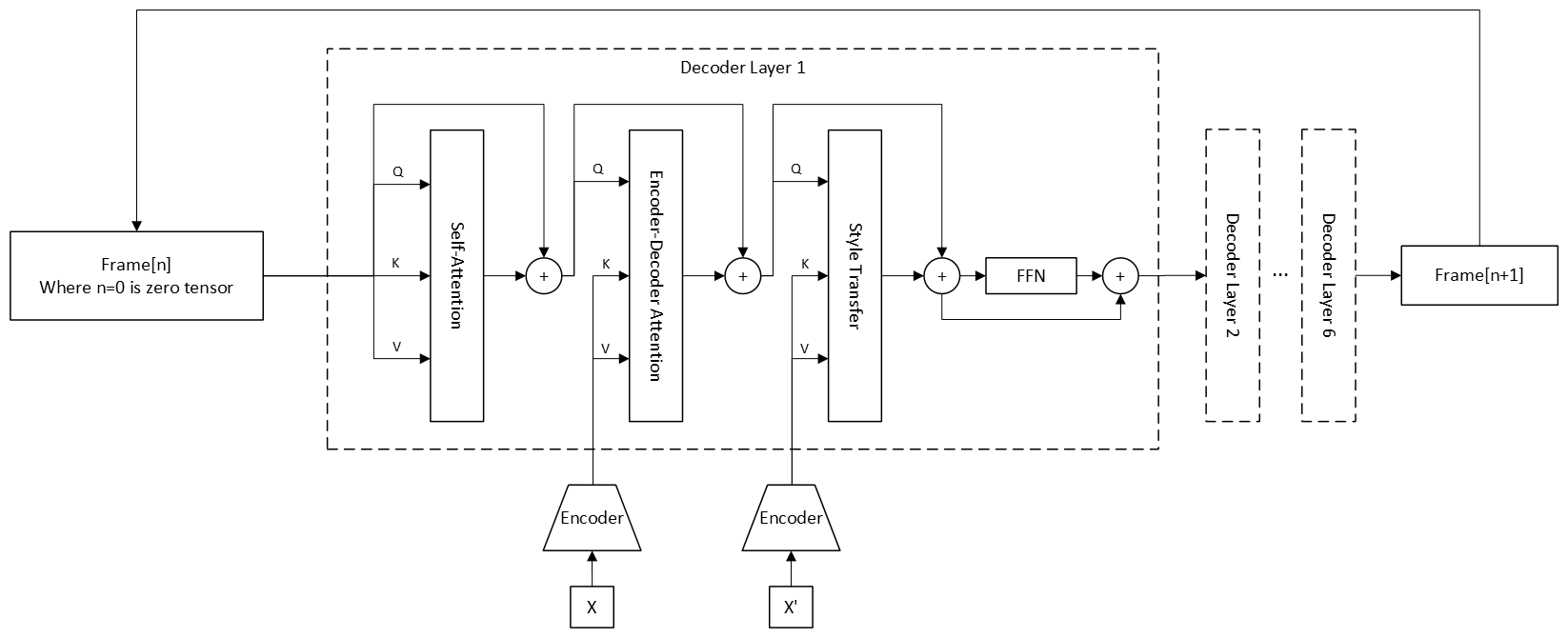
3. Autoregressive Decoder
Cross-Attention Transformer
Inspired by Style Transfer ($\text{StyTr}^2$)*, the decoder attends to Action (Content) and Identity (Style) separately.
There is no existing Transformer Decoder for Skeleton-based Data or Motion Retargeting.
Autoregressive Generation
It generates frame $t$ based on $t-1$, ensuring temporal continuity.
* Y. Deng et al., "Stytr2: Image style transfer with transformers," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11326-11336, 2022.
Training Strategy
To prevent mode collapse and ensure disentanglement, we employ a 3-Stage Training Process.
Stage 1: Encoders
Objective: Disentanglement
We train only the Encoders ($E_A, E_I$).
- Goal: Force $E_A$ to capture Dynamics and $E_I$ to capture Structure.
- Method: Use auxiliary tasks to maximize separation (e.g., $E_A$ should not predict Identity).
Stage 2: Decoder
Objective: Reconstruction
We freeze Encoders and train only the Decoder.
- Goal: Learn to generate smooth motion sequences from the disentangled features.
- Method: Teacher Forcing: We feed Ground Truth history to stabilize autoregressive learning.
Stage 3: Fine-Tuning
Objective: Integration
We unfreeze all components.
- Goal: Jointly optimize the pipeline for both Privacy and Utility.
- Method: End-to-End training with a low learning rate to refine the boundaries.
Evaluation Plan
Metrics
- Privacy: Re-ID (Top-1/5). Same classifier methods as previous studies.
- Utility: Action Recognition (Top-1/5), MSE.
Generalization
We will use ETRI Dataset to evaluate cross-dataset generalization.
Target Outcomes
- Privacy: Match PMR (<10%).
- Utility: > 60% (Top-1), > 80% (Top-5).
- Generalization: Cross-Dataset (NTU -> ETRI).
Future Work: Updating AnonVis
Why update?
The quality from Study 2 (PMR) was not sufficient for visual demonstration. Study 1 was limited to White-Box settings.
Plan
We will integrate DisentangledTMR into the AnonVis VR pipeline to demonstrate high-fidelity, anonymized motion in real-time.
Study 3 Contributions
- Architecture: First Transformer-based Motion Retargeting model specifically designed for Privacy.
- Method: Explicit Gating + Inductive Bias for Disentanglement.
- Result: Closing the Privacy-Utility Gap.
Dissertation Summary
Addressing the Research Questions.
RQ1: Precision
Study 1 proved we can target specific joints using XAI.
RQ2: Agnostic Defense
Study 2 proved Motion Retargeting works as a Black-Box defense.
RQ3: Utility Gap
Study 3 proposes Transformers to restore utility.
Publications
- ISMAR 25 Carr, Thomas, et al. "AnonVis: A Visualization Tool for Human Motion Anonymization." 2025 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), 2025. (Demo)
- ICCV 25 Carr, Thomas, et al. "Privacy-centric Deep Motion Retargeting for Anonymization of Skeleton-Based Motion Visualization." Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 13162-13170.
- PAKDD 25 Carr, Thomas, et al. "Explanation-Based Anonymization Methods for Motion Privacy." Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer Nature Singapore, 2025, pp. 52-64.
- BigData 24 Carr, Thomas, and Depeng Xu. "User Privacy in Skeleton-based Motion Data." 2024 IEEE International Conference on Big Data (BigData), IEEE, 2024, pp. 8219-8221.
- MetaCom 24 Carr, Thomas, et al. "A Review of Privacy and Utility in Skeleton-based Data in Virtual Reality Metaverses." 2024 IEEE International Conference on Metaverse Computing, Networking, and Applications (MetaCom), IEEE, 2024, pp. 198-205.
- CIKM 23 Carr, Thomas, et al. "Linkage Attack on Skeleton-Based Motion Visualization." Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, 2023, pp. 3758-3762.
Dissertation Timeline
TMR Implementation
Experiments & Ablation
Submit to ECCV
Final Defense
Thank You
Questions?
tcarr23@charlotte.edu